22.07
- 22.07.31 : SwiftUI DocumentGroup, Settings
- 22.07.30 : SwiftUI WindowGroup
- 22.07.29 : SwiftUI Lifecycle
- 22.07.28 : c++ loops, SwiftUI Lifecycle
- 22.07.27 : SwiftUI App
- 22.07.17 : iterator
- 22.07.15 : container, template specialization
- 22.07.13 : template
- 22.07.12 : 왜 예외를 쓰는 게 좋을까요?
- 22.07.09 : Overloading, Overriding
- 22.07.05 : this 포인터
- 22.07.03 : 고정 소수점의 사칙연산
- 22.07.01 : 이진 나눗셈
22.07.31 : SwiftUI DocumentGroup, Settings
DocumentGroup
DocumentGroup은 문서를 열고 편집하기 위한 사용자 인터페이스를 생성하는 Scene 타입이다. 문서 데이터 모델과 문서 내용을 표시하는 뷰 계층 구조를 초기화한다. FileDocument 프로토콜을 준수하는 값 모델을 사용하거나 ReferenceFileDocument 프로토콜을 준수하는 참조 모델을 사용할 수 있다. 문서 기반 앱에서 필요한 다중 창 지원, 패널 열기 및 저장, 드래그 앤 드롭과 같은 표준 동작을 지원한다.
Value type documents
- protocol FileDocument : 문서를 직렬화하는데 사용되는 문서 모델
- struct FileDocumentConfiguration : 열린 파일 문서의 속성
Reference type documents
- protocol ReferenceFileDocument : 참조 유형 문서를 직렬화하는데 사용되는 문서 모델
- struct ReferenceFileDocumentConfiguration : 열린 참조 파일 문서의 속성
Read and write configurations
Settings
Settings는 앱의 설정을 보거나 수정하기 위한 Scene이다.
선언
개요
App 프로토콜을 사용하여 앱을 선언할 때 SwiftUI가 View를 앱의 설정대로 관리하도록 한다. 다음 예시는 macOS에서만 설정 Scene을 컴파일한다.
View를 Settings Scene의 인수로 전달하면 SwiftUI가 앱의 설정 메뉴 항목을 활성화한다. SwiftUI는 사용자가 Settings를 나타나게 하거나 사라지게 할 수 있도록 관리한다. 다음은 설정뷰에서 AppStorage 값을 변경하는 예시이다. 설정을 하나의 View에서 정의하거나 TabView를 사용하여 다른 컬렉션으로 그룹화할 수 있다.
22.07.30 : SwiftUI WindowGroup
WindowGroup
동일한 구조의 Window 그룹을 표시하는 Scene이다.
선언
개요
App에서 View 계층 구조의 컨테이너로 사용한다. 그룹 컨텐츠로 선언한 계층 구조는 App이 해당 Group에서 생성하는 각 Window에 대한 템플릿 역할을 한다.
SwiftUI는 특정 플랫폼별 동작을 처리한다. 예를 들어 macOS 및 iPadOS와 같은 플랫폼에서 사용자는 그룹에서 동시에 둘 이상의 창을 열 수 있다. macOS에서 사용자는 탭 인터페이스에서 열린 창을 함께 모을 수 있다. 또한 macOS에서 창 그룹은 표준 창 관리를 위한 명령을 자동으로 제공한다.
그룹에서 생성된 모든 창은 독립적인 상태를 유지한다. 그룹에서 생성된 각각의 새 창에 대해 시스템은 Scene의 View 계층 구조에 의해 인스턴스화된 State 또는 StateObject 변수에 대해 새 저장소를 할당한다.
일반적으로 문서 기반의 앱이 아니라면 WindowGroup을 사용하고, 맞다면 DocumentGroup을 사용한다.
Hashable과 Codable을 모두 준수하는 지정된 유형의 데이터를 표시하도록 WindowGroup을 선택적으로 정의할 수 있다. openWindow 동작과 함께 사용하면 그룹에 대한 Window가 열리고 루트 View는 제시된 값에 대한 바인딩을 전달한다. 바인딩이 표시되는 것과 동일한 값을 갖는 창이 이미 존재하는 경우 해당 창이 대신 앞으로 표시된다. 바인딩 값은 State 복원을 위해 유지되고 Window가 복원될 때 디코딩된다. 그러면 바인딩이 디코딩된 값으로 설정된다. 디코딩 과정에서 오류가 발생하면 바인딩이 기본값 또는 nil로 설정된다. 일반적으로 보여주는 값은 가벼운 데이터를 사용하는 것이 좋다. Identifiable을 준수하는 구조화된 모델 값의 경우 값의 식별자가 잘 작동한다. 다음 예시는 새 창에서 지정된 메모 항목을 여는 버튼을 정의한다.
22.07.29 : SwiftUI Lifecycle
ScenePhase
애플이 iOS14부터 ScenePhase를 제공했다. ScenePhase는 @Environment 속성 래퍼를 사용하여 가져오고, onChange(of:) 수정자를 사용하여 변경사항을 받을 수 있다.
- App is active : 앱이 켜진 직후
- App is inactive : 앱 스위칭 할 수 있게 올린 상태
- App is in baskgroud : 아이폰 홈 화면으로 나온 상태
22.07.28 : c++ loops, SwiftUI Lifecycle
어떤 반복문을 사용해야 하는지 의문이 들었다. index를 사용한 반복문이 iterator를 사용한 반복문보다 빠르다는 사실을 알게된 이후로 생긴 의문이다. 검색해보니 컨테이너에서 반복문을 사용하는 방법을 정리한 글을 찾게 되었다.
- index-based iteration
장점: C 스타일로 친숙하며, 다른 보폭으로 루프가 가능하다 (예를 들어
i += 2)
단점: 순차 랜덤 액세스 컨테이너(vector,array)의 경우에만 작동하고, 연관 컨테이너(deque)에서는 작동하지 않는다. 루프 제어가 약간 장황하다(초기화, 확인, 증가).
- iterator-based iteration
장점: 모든 컨테이너에서 작동한다. 연관 컨테이너에서도 사용할 수 있다. 다른 보폭으로 루프가 가능하다. (std::advance(it, 2))
단점: 현재 요소의 인덱스를 가져오려면 추가 작업이 필요하다. 루프 제어가 약간 장황하다. (초기화, 확인, 증가)
- STL for_each algorithm + lambda
장점: iterator-based iteration과 같으며 루프 제어에서 확인과 증가를 하지 않아도 되기 때문에 버그 비율을 줄일 수 있다. (잘못된 초기화, 확인 또는 증가, 하나씩 오류)
단점: 명시적 반복자 루프와 동일하고 루프의 흐름 제어에 대한 제한된 가능성(continue, break, return 사용 불가) 및 다른 보폭이 대한 옵션이 없다.
- range-for loop
장점: 매우 컴팩트한 루프 제어, 현재 요소에 대한 직접 액세스.
단점: 인덱스를 얻기 위한 추가 명령문. 다른 보폭을 사용할 수 없다.그래서 무엇을 사용해야 하는가?
std::vector의 경우에 index가 필요하거나 다른 보폭이 필요한 경우에 indexed-loop, 아니면 range-for 루프를 사용한다.
일반 컨테이너에 대한 일반 알고리즘의 경우, 루프 내부에 흐름 제어가 필요하고 다른 보폭이 필요하다면 iterator-loop, 아니면for_each + a lambda를 사용한다.SwiftUI Scene
Scene
Scene은 시스템에서 관리하는 수명 주기가 있는 App 사용자 인터페이스의 일부를 나타낸다. App 인스턴스는 포함된 장면을 표시하지만 각 Scene은 뷰 계층 구조의 루트 요소 역할을 한다.
시스템은 Scene의 타입, 플랫폼 및 컨텍스트에 따라서 다양한 방식으로 Scene을 제시한다. Scene은 전체 디스플레이, 디스플레이의 일부, 창, 창의 탭 등을 채울 수 있다. 경우에 따라 앱이 한 번에 둘 이상의 Scene 인스턴스를 표시할 수도 있다.
뷰를 구성하는 방법과 유사하게 수정자를 사용하여 Scene을 구성한다. 예를 들어 Scene이 포함된 창의 모양을 windowStyle 수정자로 조정할 수 있다.
App의 body에 Scene protocol을 준수하는 하나 이상의 인스턴스를 결합하여 App을 만든다. SiwftUI가 제공하는 기본 Scene을 사용하거나 다른 Scene에서 구성한 사용자 지정 Scene을 포함할 수 있다. 사용자 정의 Scene을 만들려면 Scene protocol을 준수하는 유형을 선언하면 된다.
Scene은 사용자에게 표시하여는 뷰 계층 구조의 컨테이너 역할을 한다. 시스템은 앱의 현재 상태에 따라 사용자 인터페이스에 뷰 계층 구조를 표시할 시기와 방법을 결정한다. 예를 들어 창 그룹의 경우 시스템에서 사용자가 macOS 및 iPadOS와 같은 플랫폼에 포함된 창을 생성하거나 제거할 수 있다. 다른 플랫폼에서는 동일한 뷰 계층 구조가 활성 상태일 때 전체 디스플레이를 사용할 수 있다.
Scene 또는 해당 View 중 하나에서 환경 값을 읽어서 장면이 활성 상태인지 아니면 다른 상태인지 확인할 수 있다. 환경 속성을 사용하여 Scene의 단계를 포함하는 속성을 만들 수 있다.
Scene protocol은 Scene을 구성하는데 사용하는 기본 수정자를 제공한다. 이 수정자는 프로토콜 메서드로 정의되어 있다. 예를 들어 onChange 수정자를 사용하여 값이 변경되는 작업을 트리거할 수 있다. 그리고 창 그룹의 모든 Scene이 배경으로 이동할 때 캐시를 비운다.
ScenePhase
Scene의 작동 상태를 나타낸다.
시스템은 장면의 작동 상태를 반영하는 단계를 통해 앱의 Scene 인스턴스를 이동시킨다. 단계 변경을 트리거하여 사용할 수 있다. 다음 예제는 Environment에서 scenePhase 값을 관찰하여 현재 단계를 읽는다.
값을 해석하는 방법은 값을 읽은 위치에 따라 다르다.
View 인스턴스 안에서 scenePhase를 읽으면 View가 포함된 scene의 단계를 반영하는 값을 얻는다. 다음 예제는 onChange 메서드를 사용하여 둘러싸이는 scene이 ScenePhase.active 단계에 들어갈 떄마다 타이머를 활성화하고 다른 단계에 들어갈 때 타이머를 비활성한다.
만약에 App 인스턴스 안에서 scenePhase를 읽으면 모든 scene의 단계를 반영하는 집계 값을 얻는다. 앱은 활성화된 scene이 있는 경우 ScenePhase.active 값을 보고하고, 아닌 경우에는 ScenePhase.inactive 값을 보고한다. 여기에는 단일 scene 선언에서 생성된 여러 scene 인스턴스가 포함된다. WindowGroup에서 ScenePhase.backgroud 단계에 들어가면 앱이 곧 종료된다고 예상할 수 있다.
만약에 custom Scene에서 읽는다면 값은 custom scene을 구성하는 모든 scene의 집계를 유사하게 반영한다.
Getting scene phase
case active: scene이 앞에 있으며 반응하고 있다.case inactive: scene이 앞에 있지만 작업이 중단되어 있다.case background: scene의 현재 UI가 보이지 않는다.SwiftUI Lifecycle
SwiftUI’s New App Lifecycle and Replacements for AppDelegate and SceneDelegate in iOS 14
SwiftUI는 UIKit의 AppDelegate와 SceneDelegate에서 벗어나기 위해서 새로운 라이프 사이클을 가진다. 이를 위해 iOS 14는 App Protocol, SceneBuilder, scenePhase enumerator, UIApplicationDelegateAdapter를 제공한다. 이들을 살펴보기 전에 SceneDelegate를 빠르게 훑어본다.
SceneDelegate는 iOS 13에 iPadOS의 다중 창 지원을 해결하기 위해 도입되었다. 이는 window 개념에서 scene 개념으로 전환되며 AppDelegate의 책임이 분리되었다.
iOS 14에서부터 새로운 SwiftUI 애플리케이션 프로젝트를 생성할 때
SwiftUI App Lifecycle과UIKit App Delegate중에서 선택할 수 있게 되었다. 후자를 사용하는 경우에는 예전과 같이 AppDelegate와 SceneDelegate 보일러 플레이트 코드와 UIHostingController가 SwiftUI View를 포함하는데 사용된다. 하지만 전자를 사용하면 완전히 새로운 출발점의 SwiftUI를 맞이하게 된다.SwiftUI App Protocol: 새로운 시작점
위의 코드는 짧지만 많은 작업이 자동으로 이루어진다. 기본적으로 구조체는 Scene과 View을 한 곳에 통합하여 SwiftUI 애플리케이션 계층 구조에 대한 조감도를 제공한다. 코드를 작성하는데 주의할 점은 다음과 같다.
@main속성은 위의 구조체가 SwiftUI 애플리케이션의 시작점임을 나타낸다.- App protocol을 준수하며 하나 이상의 scene을 구성하기위한 SceneBuilder를 구현해야 한다.
- 위의 예에서 WindowGroup은 SwiftUI view를 감싸는 컨테이너 scene이다. iPadOS나 macOS는 위의 애플리케이션을 실행하며 여러 WindowGroup scene을 생성하는 기능을 지원한다.
WindowGroup 외에도 DocumentGroup을 사용하거나 WKNotificationScene와 같은 scene 타입을 사용할 수 있다.
WindowGroup scene에서 명령어 수정자를 사용하여 단축키를 설정할 수 있다. 이를 위해서는 새로운 CommandBuilder를 활용하여 Commands protocol을 사용하는 CommandMenu를 그룹화해야 한다.
복잡한 Scene을 구성할 때는 계산된 속성을 @SceneBuilder로 반드시 설정해야 한다. 예를 들어 아래의 코드는 macOS 플랫폼에 대한 환경 설정 메뉴 장면을 생성한다.
How to Listen to SceneDelegate Lifecycle Methods?
SceneDelegate에서와 같이 scene의 수명 주기 업데이트를 수신하기 위해서는 scenePhase 열거자를 사용한다. 이를 환경 속성 래퍼 및 onChange 수정자에 사용하여 scene의 상태 변경을 수신할 수 있다.
How to Use AppDelegate With SwiftUI App Protocol
AppDelegate 클래스는 애플리케이션의 중요한 부분이다. 알림 처리를 하든지 Firebase 처리를 하든지 다양한 수명 주기 방식으로 중요한 역할을 한다.
AppDelegate 기능을 연결하기 위해서 UIKit을 SwiftUI 애플리케이션으로 가져와야 한다. SwiftUI는 새로운 속성 래퍼인 UIApplicationDelegateAdaptor를 제공한다. 이를 통해 AppDelegate를 SwiftUI 구조에 주입할 수 있다.
22.07.27 : SwiftUI App
App structure and behavior
SwiftUI는 UIKit의 AppDelegate와 SceneDelegate 대신에 다른 라이프 사이클을 가진다.
App protocol을 준수하는 타입을 만들고 이를 사용하여 유저 인터페이스를 구성한다. 데이터 모델 객체를 관리하기 위해서StateObject를 사용하여 객체를 인스턴스화하고 앱 구조를 감싼다.라이프 사이클 반응에 대한 작업을 해야하는 경우에는 적절한 scene에 onChange같은 수정자를 추가하여 scene의 변화를 확인할 수 있다. view에서도 마찬가지로 수정자를 사용할 수 있다.
만약에 UIKit이나 AppKit, WatchKit에서 구현하듯이 앱의 delegate를 만들어 callback에 응답해야한다면 적절한 delegate adaptor 속성 레퍼를 사용할 수 있다.
App
앱의 구조와 동작을 나타내는 타입이다.
App프로토콜을 준수하는 구조를 선언하여 앱을 만든다.body는 앱의 콘텐츠를 정의하는데 필요한 속성을 계산한다.
@main은 앱의 진입점을 나타낸다.App protocol구조체 선언 앞에 붙여서 시스템이 앱을 시작하기 위한 메서드에 기본 구현을 알려준다. 앱 파일은 단 하나의 진입점을 가질 수 있다.
Scene protocol을 준수하는 인스턴스에서 앱의 body를 구성한다. 각각의 scene은 계층 구조의 루트뷰를 포함하고 있으며, 시스템에서 관리하는 라이프 사이클이 있다. 기본적으로 제공하는 scene 타입이 있으며, 사용자 지정 scene을 만들 수 있다.
앱에서 상태를 선언하여 앱의 모든 scene에서 공유할 수 있다. 다음의 코드와 같이
StateObject속성을 사용하여 데이터 모델을 선언하고, 모델을ObservedObject로 뷰의 인자로 제공하거나EnvironmentObject로 환경을 통해 제공할 수 있다.
22.07.17 : iterator
iterator
반복자는 어떤 컨테이너에 접근하든 동일한 방법으로 접근하기 위해 제공되는 객체이다.
원소의 위치를 가지고 있는 포인터와 비슷한 형태이다.
vector는 연속된 메모리 공간을 가지고 있어서 인덱스 연산으로 임의 접근이 가능하고, 증가시키며 순회도 가능하다. 하지만 list의 경우에는 연속된 메모리 공간을 가지고 있지 않고, 현재 가리키고 있는 노드에서 다음 노드의 주소로 갱신하는 방식으로 순회를 진행한다. 이렇게 컨테이너마다 요소에 접근하는 방식이 다르므로 반복자를 사용하여 컨테이너의 내부 구조를 몰라도 어떤 컨테이너든지 통일된 인터페이스를 가지게 된다.iterator categories
반복자는 지원하는 속성에 따라 5가지로 분류된다. (입력, 출력, 순방향, 양방향, 임의 액세스)
- 입력 반복자 : 순차 입력 작업에 사용할 수 있는 반복자이며, 반복자가 가리키는 각 값은 한번 읽은 다음 반복자가 증가한다.
- 출력 반복자 : 순차 출력 작업에 사용할 수 있는 반복자이며, 반복자가 가리키는 각 값은 한번 쓴 다음 반복자가 증가한다.
- 순방향 반복자 : 시작에서 끝으로 가는 방향으로 범위의 요소 시퀀스에 엑세스하는 데 사용할 수 있는 반복자이다. 여러 복사본을 사용하여 동일한 반복자 값을 두번 이산 전달할 수 있다. 증가만 지원하고 감소는 지원하지 않는다.
- 양방향 반복자 : 범위의 요소 시퀀스에 양방향으로 액세스하는 데 사용할 수 있는 반복자이다. 순방향 반복자와 동일한 속성을 가지며 감소할 수 있다.
- 임의 엑세스 반복자 : 어떠한 요소의 위치에서 임의 오프셋 위치에 있는 요소에 접근할 수 있다.
iterator range
range란 컨테이너에 담긴 값들의 시퀀스를 말한다. 한 쌍의 반복자는 이 시퀀스의 시작과 끝을 가리켜서 값들의 구간을 설정하는데 사용될 수 있다. 두개의 반복자는 같은 컨테이너로부터 생성되어야 하며, 첫번째 반복자는 두번째 반복자의 앞에 와야한다.
end()
end함수는 컨테이너의 마지막 반복자를 생성하기 위해 호출된다. 이 반복자는 컨테이너의 마지막 원소를 가리키지 않고, 마지막 원소의 다음 공간을 가리킨다. 아무 의미가 없는 공간을 가리키고 있으므로 참조하면 오류가 발생된다.
22.07.15 : container, template specialization
Container
- Standard sequence container (vector, deque, list)
- vector : 크기가 변할 수 있는 배열을 나타내는 시퀀스 컨테이너이다.
- 배열과 달리 크기가 동적으로 변경될 수 있으며 저장공간은 컨테이너에서 자동으로 처리된다.
- 내부적으로 vector는 동적으로 할당된 배열을 사용하여 요소를 저장한다.
새 요소가 삽입될 때 크기를 늘려야 한다면 새 배열을 할당하고 모든 요소를 옮긴다.
- 컨테이너 속성
- Sequence : 요소는 엄격한 선형 시퀀스로 정렬된다. 개별 요소에 해당 위치로 접근된다.
- Dynamic array : 포인터로 모든 요소에 직접 접근할 수 있으며, 끝에 추가/제거를 빠르게 할 수 있다.
- Allocator-aware : 저장공간을 동적으로 처리한다.
- deque(double ended queue) : 양방향 큐는 양쪽 끝에서 확장하거나 축소할 수 있는 동적 크기의 시퀀스 컨테이너이다.
- 일반적으로 동적 배열의 일부 형태로 다양한 방식으로 구현될 수 있다.
- 개별 요소는 임의 접근 반복자를 통해 직접 접근할 수 있다.
- 필요에 따라서 컨테이너를 확장 및 축소하여 저장 공간을 자동으로 처리할 수 있다.
- vector와 유사하지만 시작 부분에도 요소를 효율적으로 삽입/삭제한다.
- 모든 요소가 인접한 저장 위치에 저장된다고 보장하지 않으므로 다른 요소에 대한 포인터를 오프셋하여 접근하면 정의되지 않은 동작이 발생한다.
- 시작과 끝이 아닌 위치에 요소를 삽입/제거하는 작업의 경우에 list보다 성능이 저하되고 반복자와 참조의 일관성이 떨어진다.
- list : 시퀀스 내에서 어느 곳에나 삽입/제거를 일정한 시간에 수행하고 양방향으로 반복할 수 있는 시퀀스 컨테이너이다.
- list는 이중 연결 리스트로 구현된다.
- 이중 연결 리스트는 서로 관련 없는 저장 위치에 포람된 각 요소를 저장할 수 있다.
- list는 일반적으로 반복자가 이미 확보된 컨테이너 내의 모든 위치에서 요소의 삽입/추출/이동에서 좋은 성능을 보이기 때문에 이러한 속성을 사용하는 알고리즘에서 수행된다.
- 주요 단점은 위치별로 요소에 직접 접근할 수 없다. 시작이나 끝같은 위치에서 해당 위치까지 반복해야 하므로 선형 시간이 걸린다.
Template specialization
템플릿의 특정 패턴에 대해서 별도의 처리가 하고 싶은 경우에 사용할 수 있다.
예를 들어 다음과 같은 상황이 있을 수 있다.
int타입인 경우에는 정상적으로 크기를 비교하지만,const char *타입인 경우에는 단순히 주소를 비교하여 출력된다.
위의 코드에 특수화를 사용하여 제대로 동작하도록 수정하면 다음과 같다.
char*,const char*타입의 함수를 직접 명시하므로 컴파일러가 해당 타입 함수가 필요할 때 임의대로 만들지 않고 명시된 함수를 사용하도록 만든다.
22.07.13 : template
template는 함수나 클래스를 개별적으로 다시 작성하지 않아도, 여러 자료형으로 사용할 수 있도록 만들어 놓은 틀이다.
template는 Function Template와 Class Template로 나뉘어진다.
template 매개변수는 타입을 인수로 전달하는데 사용할 수 있는 특별한 종류의 매개변수이다. template를 선언하는 형식은 다음과 같다.
Function Template
함수를 정의할 때, 함수의 기능은 명확하지만 자료형을 모호하게 둔다. c++에서는 다형성의 오버로딩 특성에 의해서 함수 이름이 같아도 되기 때문에 다음과 같이 함수를 정의하게 된다.
인자의 타입을 다르게 하여 같은 이름의 함수를 반복적으로 정의해야 한다. 이렇게 반복해야하는 문제를 해결하기 위해 template를 사용한다. 다음은 위의 코드를 template로 작성한 코드이다.
두개의 인자가 타입이 다른 경우
이 함수 템플릿을 사용하기 위해서는 다음과 같은 형식을 사용한다.
만약에 위에 구현된 함수를 호출하는 경우에는 다음과 같이 작성할 수 있다.
컴파일러는 템플릿 함수에 대한 호출을 만나면 실제 템플릿 매개 변수로 전달된 타입으로 대체하는 함수를 자동으로 생성한 다음 호출한다.
위의 예에서는 함수 템플릿 sum()을 두번 사용했다. 처음에는 int 타입의 인수를 사용하고, 다음은 long 타입의 인수를 사용했다. 컴파일러는 적절한 함수를 인스턴스화한 다음에 호출한다.
T타입이 sum() 템플릿 함수안에서 객체를 선언하는 데에도 사용된다.컴파일러는 각 호출에 필요한 타입을 자동으로 결정한다. 템플릿 함수가 동일한 타입의 인수가 들어올 것이라고 예상하고 있기 때문에 다른 타입의 인수를 보내면 컴파일 에러가 발생한다. 만약에 두 인수의 타입을 다르게 한다면 다음과 같이 둘 이상의 타입 매개 변수를 허용하는 함수 템플릿을 정의할 수도 있다.
이 경우에 다른 두 매개변수를 허용하고 함수는 T 유형의 객체를 반환한다.
클래스 템플릿
클래스 템플릿을 작성하여 템플릿 매개변수를 유형으로 사용하는 멤버를 가질 수 있다.
이 클래스의 객체를 선언하여 사용하려면 다음과 같이 작성할 수 있다.
클래스 템플릿 선언의 외부에 함수 멤버를 정의한다면 정의 앞에 템플릿 <…> 점두사를 붙여야 한다.
템플릿 전문화
다음은 클래스 템플릿 전문화에 사용되는 구문이다.
클래스 템플릿 이름 앞에 빈 template<> 매개변수 목록이 된다. 템플릿 전문화를 명시적으로 선언하는 것이다. 이 접두사보다 더 중요한 것은 클래스 템플릿 이름 위에있는
매개변수이다. 이 특수화 매개변수 자체는 템플릿 클래스 특수화를 선언할 유형을 식별한다. 일반 클래스 템플릿과 전문화 간의 차이점을 확인할 수 있다.
템플릿에 대한 비유형 매개변수
유형을 나타내는 class 또는 typename 키워드 대신에 일반 타입 매개변수를 가질 수도 있다. 일반 타입 매개변수를 설정하면 다음과 같이 정의된다.
22.07.12 : 왜 예외를 쓰는 게 좋을까요?
c++에 예외가 도입된 이유를 생각해볼 필요가 있다. Java와 c# 같은 언어가 c++의 예외를 물려받은 이유는 결함내성 소프트웨어를 쉽게 작성하기 위함이다. 에러 처리를 한 후에도 일관성있는 상태를 유지해야 한다는 사실은 결함 내성을 달성하기 까다롭게 만든다.
어떤 파일을 열고 데이터를 읽어들이는 C코드를 생각해본다.
OpenAndRead()는 모든 서브루틴이 잘 수행된다는 가정을 한다면 잘 작동하고 읽기 쉽다. 하지만 fn 파일이 없는 경우, malloc()이나 fgets()가 실패되어 에러가 발생할 가능성이 있다. 이 코드를 결함내성이 있게 만드려면 각 서브루틴이 호출된 후에 에러가 발생하는지 확인하고, 어떤 행동을 해야하는지 결정해야한다. 단순히 에러 메시지를 출력하고 자원을 해제한 후에 -1을 반환하도록 바꾸어 보면 다음과 같을 것이다.
이 코드는 에러를 처리하지만 읽기 어렵다. 알고리즘과 에러 처리가 섞여있기 때문인데 이 문제를 예외를 발생시키는 방법으로 변경할 수 있다.
OpenAndRead() 주 제어 흐름이 에러 처리와 분리되어 읽기 쉬워졌다. 하지만 아직 라인 수가 많다. 여기에서 예외가 발생했을 때 이루어지는 스택 풀기 과정을 이해하면 코드 라인 수를 줄일 수 있다.
스택 풀기는 예외가 발생하면 예외 처리기를 만나기 전까지 스택을 풀어가는 과정을 말한다. c++ 에서는 try 영역에서 생성된 모든 자동 객체들에 대해 소멸자를 불러온다. 자동 객체들은 생성되었던 반대 순서로 소멸된다.
자원을 소유하는 객체들을 자동 객체로 정의하면 예외가 발생하더라도 자동적으로 소멸된다. 이런 프로그래밍을 가능하게 만드는 자원 소유 객체들이 파일이나 메모리에 이미 정의되어 있다. 파일 자원용으로 std::fstream, 메모리 자원용으로는 boost::scoped_ptr을 사용할 수 있다. 이 객체를 사용하면 다음과 같이 구현할 수 있다.
c++ 런타임이 모든 자원 해제를 알아서 해주기 때문에 에러 코드에 자원 해제 코드를 추가하지 않아도 된다. OpenAndRead()가 상당히 간단해졌다.
예외를 사용하는 경우에 다음과 같은 문제도 해결할 수 있다. 만약에 에러가 발생한 원인을 알고 싶지만 OpenAndRead를 호출하는 시점이 멀리 떨어져 있다면 어떻게 원인을 알 수 있는지 생각할 수 있다. 다음과 같은 상황에서는 원인을 파악할 수 없다.
OpenAndRead()는 반환 코드를 통해서 에러를 구분하려 하지만 foo()에서 무시하여 bar()는 무슨 일이 일어났는지 알 수 없다. bar()가 할 수 있는 일은 에러 메시지를 출력하고 종료하거나 에러를 무시할 수 밖에 없다. 이런 문제는 예외를 사용하여 해결할 수 있다. 호출 경로상의 어떤 함수가 예외를 처리하지 않고 무시하면 된다. OpenAndRead()와 foo()는 예외를 어떻게 처리해야 할지 모른다고 가정하고, bar()는 처리할 수 있다고 가정한다면 다음과 같이 구현된다.
이제는 OpenAndRead()와 foo()가 다시 간단해졌고, bar()만 에러 처리에 관여하고 있다. 그리고 예외가 무엇을 의미하는지 알고 충분한 상황 정보가 있기 때문에 예외를 잘 처리할 수 있다.
또 한가지 예외의 장점은 객체라는 점이다. 객체이기 때문에 많은 정보를 담아서 발생시키면 정확한 에러 상황을 알 수 있다. 예외 처리기는 그 정보들이 접근하여 어떤 일이 벌어지고 있는지 정확히 알아내는데 도움이 된다.
intptr_t, uintptr_t
intptr_t와 uintptr_t는 포인터의 주소를 저장하는데 사용된다.
안전한 포인터 선언 방법으로 제공하기 때문에 포인터를 정수 표현으로 변환할 때 유용하게 사용할 수 있다. 포인터 주소를 정수값으로 가지고 있기 때문에 연산이 가능하다. 특히 비트연산을 하는 경우에 사용된다. 비트 연산은 unsigned에서 더 잘 수행되기 때문에 uintptr_t를 하면 된다.다음 예시는 포인터가 포인터 배열인지 테스트한다.
22.07.09 : Overloading, Overriding
overloading과 overriding은 이름이 비슷해서 헷갈리는 경우가 있다.
overloading은 같은 이름의 함수를 여러개 정의하고, 매개변수의 유형과 개수를 다르게하여 다양한 유형의 호출에 응답할 수 있게 만든다.
overriding은 상위 클래스가 가지고 있는 멤버함수를 하위 클래스의 메서드로 재정의해서 사용한다. 부모 클래스의 메서드를 무시하고 자식 클래스의 메서드 기능을 사용한다.overloading은 매서드의 이름만 같고, 매개변수와 리턴 타입이 달라도 되지만 override는 메서드 이름과 매개변수, 리턴타입이 모두 같아야 한다.
22.07.05 : this 포인터
c++에서 클래스의 멤버 함수를 호출할 때 객체를 어떻게 찾을까?
숨겨진 포인터인 this를 사용한다. 멤버 함수를 컴파일 단계에서 다음과 같이 변환한다.
멤버 함수의 인수로 객체의 주소가 전달된다. 멤버 함수의 정의도 컴파일러에 의해 변환된다. 객체에 this 포인터를 추가하여 멤버 함수 안의 변수가 멤버 함수를 호출한 객체를 참조하도록 한다.
그러나 명시적으로 this를 참조해야하는 경우가 있다.
- 멤버 변수와 이름이 같은 매개 변수를 가진 멤버 함수
- 멤버 함수 체이닝 기법
멤버 함수가 this를 반환하면 체이닝 기능이 있는 함수를 만들 수 있다.
22.07.03 : 고정 소수점의 사칙연산
소수점 연산을 빠르게 처리해야하는 상황에서 고정 소수점 연산은 부동 소수점 연산에 비해 2~3배 이상 속도 차이가 난다.
부동 소수점 연산은 실수형 숫자를 저장하는 방식이 정수형에 비해 매우 복잡하다.
그래픽에서 부동 소수 계산은 필수적이고 계산량이 많기 때문에 빠르게 부동 소수를 처리하는 방법을 고안했다.
그 방법이 고정 소수점 연산이다.고정 소수점 연산이란 정수형을 이용하여 소수의 정수부와 소수부를 저장하도록 하는 수치해법적인 방법이다.
복잡한 실수형 연산을 단순한 정수의 사칙연산으로 간소화하는 방법이다.고정 소수점
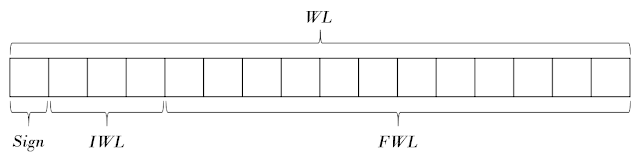
고정 소수점은 특정 숫자의 소수점 위치를 고정하는 방식이다.
소수점 위치의 설정은 사용자가 임의대로 정하면 된다.
Sign - 부호를 표현하기 위한 비트 IWL - Integer Word Length, 정수부를 표현하는 비트 수 FWL - Fractional Word Length, 소수부를 표현하는 비트 수 WL - Word Length, 전체 비트 수
사칙 연산
고정 소수점의 덧셈, 뺄셈은 정수의 덧셈, 뺄셈과 완전히 동일하다. 따라서 다른 구현이 필요하지 않다.
그러나 곱셈과 나눗셈의 경우는 그렇지 않다. 고정 소수점의 곱셈과 나눗셈의 과정에서 손실없이 정확한 결과를 얻기 위해서는 다른 방법을 사용해야 한다.
16비트의 공간을 사용한 고정 소수점은 연산을 위해 2배인 32비트 크기의 여분 공간을 활용하여 진행한다.
곱셈과 나눗셈의 과정을 보면 복잡하지만 결과값의 소수점 위치에 집중한다면 간단하게 구현할 수 있다.같은 IWL을 가진 고정 소수점 끼리의 연산을 가정한다. 그렇다면 이들은 FWL도 같다.
FWL을 L이라고 정하고, 소수점을 찍지 않은 상태의 정수 값을 각각 a, b라고 한다면 다음과 같이 고정 소수점 수를 분수로 나타낼 수 있다.
그림에서 보이듯이 덧셈과 뺄셈은 정수와 동일하게 진행되지만 곱셉과 나눗셈의 경우에는 추가적인 연산이 필요하다. 그리고 연산 과정 중에 데이터 손실이 일어날 수 있다.
곱셈은 $a \times b$ 에 $2^L$ 을 나누어주고, 나눗셈은 $a \times 2^L$ 를 계산하고 $b$ 를 나누어준다.
이때 연산을 위한 여분의 공간이 없다면 overflow가 발생하여 원하는 값을 얻지 못할 수 있다.64bit를 지원하지 않는 컴파일러를 사용해야하는 상황에서 32bit로 이 문제를 해결해본다.
bit shift를 이용하여 곱셈과 나눗셈을 한다면 두개의 32bit를 연결할 수 있다.
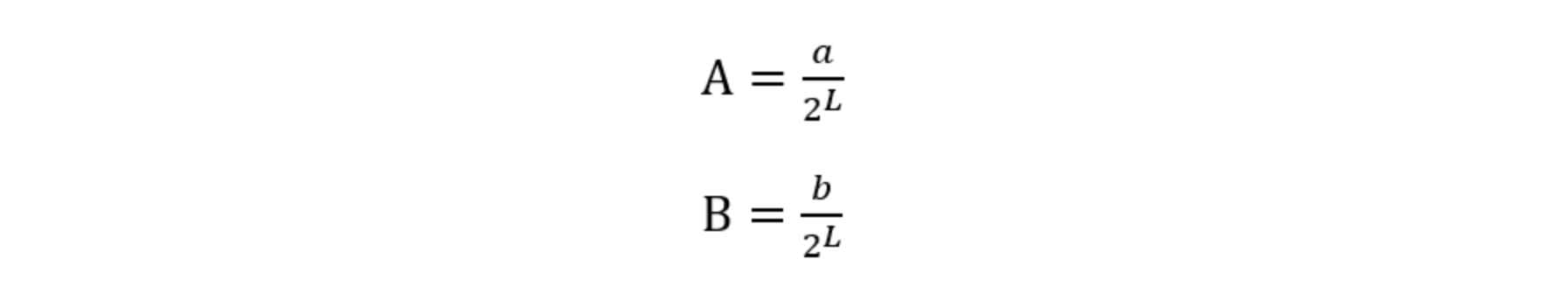
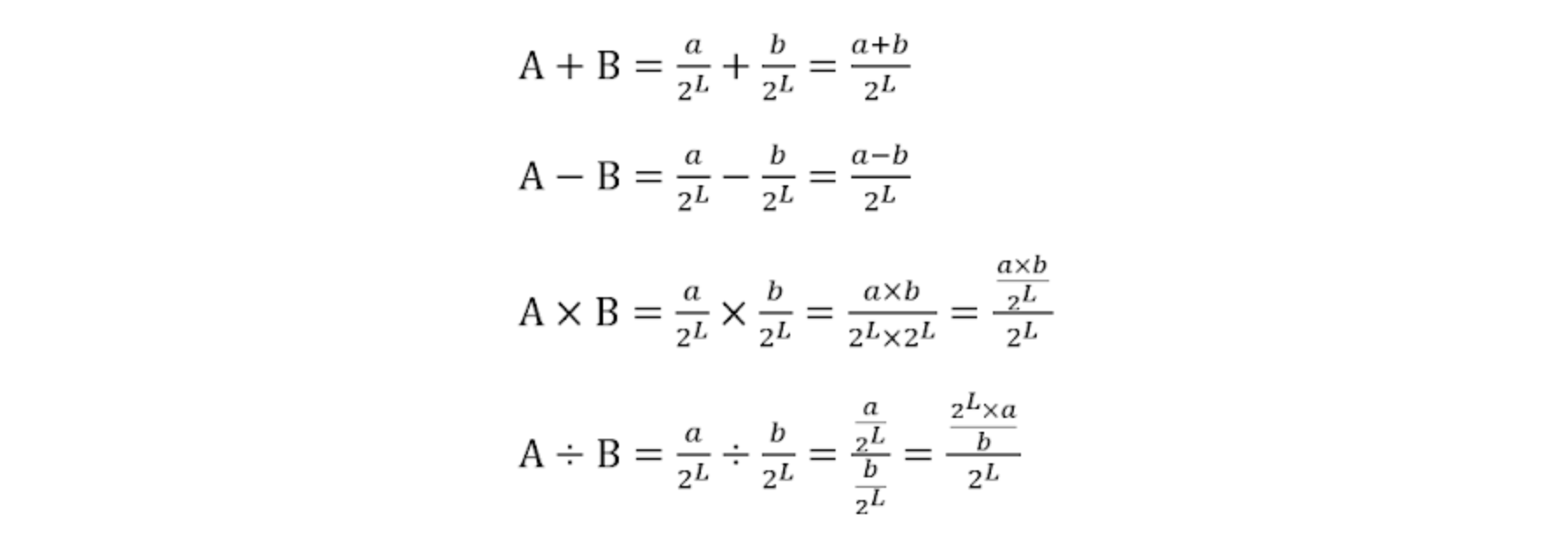
22.07.01 : 이진 나눗셈
이진 나눗셈이 십진수의 나눗셈과 큰 차이가 있지는 않지만 알고리즘이 생각만큼 이해하기 쉽지 않다.
특히 음수와 양수의 나눗셈, 혹은 음수끼리의 나눗셈까지 고려해야한다면 더욱 그렇다.$13 \div 5$ 를 5bit의 이진수로 간단히 나타내보면 $01101 \div 00101$ 이다.
이를 Shift Operator를 이용하여 계산해본다.몫은 Quotient이므로 $Q$로 나타내고, 제수는 Divisor이므로 $D$, 나머지는 Reminder이므로 $R$로 나타낸다.
$D$가 5bit이면 $Q$와 $R$을 5bit로 정할 수 있다.
$R$ $Q$ $D$ 00000 01101 00101 $R$ 과 $Q$ 가 구분되어 있지만 사실은 아래처럼 연결되어 있는 상태이며, 계산 과정에서도 아래와 같은 상황에 있다고 생각해야 한다.
$R, Q$ $D$ 00000 01101 00101 Step 1
$R$ 과 $Q$ 를 왼쪽으로 1비트씩 움직인다.
( $00000\;01101 « 1 = 00000\;11010$ )
$R$ $Q$ $D$ 00000 11010 00101 $R$ 과 $D$ 를 비교해보면 $R$ 이 더 작으므로 넘어간다.
Step 2
$R$ 과 $Q$ 를 왼쪽으로 1비트씩 움직인다.
( $00000\;11010 « 1 = 00001\;10100$ )
$R$ $Q$ $D$ 00001 10100 00101 $R$ 과 $D$ 를 비교해보면 $R$ 이 더 작으므로 넘어간다.
Step 3
$R$ 과 $Q$ 를 왼쪽으로 1비트씩 움직인다.
( $00001\;10100 « 1 = 00011\;01000$ )
$R$ $Q$ $D$ 00011 01000 00101 $R$ 과 $D$ 를 비교해보면 $R$ 이 더 작으므로 넘어간다.
Step 4
$R$ 과 $Q$ 를 왼쪽으로 1비트씩 움직인다.
( $00011\;01000 « 1 = 00110\;10000$ )
$R$ $Q$ $D$ 00110 10000 00101 $R$ 과 $D$ 를 비교해보면 $R >= D$ 이므로 $Q$ 의 첫째자리 bit를 1로 바꾼다.
$R$ $Q$ $D$ 00110 1000 100101 $R$ 를 $D$ 만큼 빼준다.
$R$ $Q$ $D$ 0000110001 00101 Step 5
$R$ 과 $Q$ 를 왼쪽으로 1비트씩 움직인다.
( $00001\;10001 « 1 = 00011\;00010$ )
$R$ $Q$ $D$ 00011 00010 00101 $R$ 과 $D$ 를 비교해보면 $R$ 이 더 작으므로 넘어간다.
$D$ 가 5bit이므로 5번째 연산에서 멈춘다.
이렇게 비트연산을 통하여 나머지와 몫을 구할 수 있다.